今天要實作的是爬取PTT表特版上的圖片,會以這篇作為示範,那就開始吧!
按右鍵檢視原始碼可以清楚找到我需要的資料,可以直接拿網址列的網址,所以就不需要開F12找隱藏網址~
接著跟前幾次練習一樣,先import需要用到的函式庫,利用get存取網址,將網頁的HTML程式碼取回來後,再來用bs4傳入剛剛拿到的的HTML程式碼。
import requests
from bs4 import BeautifulSoup
url = "https://www.ptt.cc/bbs/Beauty/M.1662872395.A.BCC.html"
response = requests.get(url)
html = BeautifulSoup(response.text, "html.parser")
print(html)
網址送出去給伺服器時會在General顯示Status Code: 302(轉址),被轉到問你是否滿18歲的網址,按下已滿18會把https://www.ptt.cc/ask/over18 送出,再被轉址成正確網址
打開F12,找到over18,其中的Response Headers會多一個set-cookie: over18=1; Path=/,代表之後再進去這個網址就不會被問問題,瀏覽器已經記住這個cookie了
cookie: 當你做過一次操作後,某些值會被存在瀏覽器,再拜訪網站時這些值會被自動送出去,像是記住帳號密碼、自動登入等
import requests
from bs4 import BeautifulSoup
url = "https://www.ptt.cc/bbs/Beauty/M.1662872395.A.BCC.html"
response = requests.get(url, cookies={"over18":"1"})
html = BeautifulSoup(response.text, "html.parser")
print(html)
requests函式庫會幫你加好基本的headers: "user-agent":"Mozilla/5.0",PTT檢查的比較寬鬆,所以不用寫滿整串也沒關係,但瀏覽有些比較嚴格的網站還是有可能會被擋下來,會顯示HTTP Error 403: Forbidden,這種時就還是要整句加滿
# 多加一句
response = requests.get(url, headers={"cookie":"over18=1", "user-agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"})
這麼一大串資料可以從Headers滑到最下面的user-agent找到。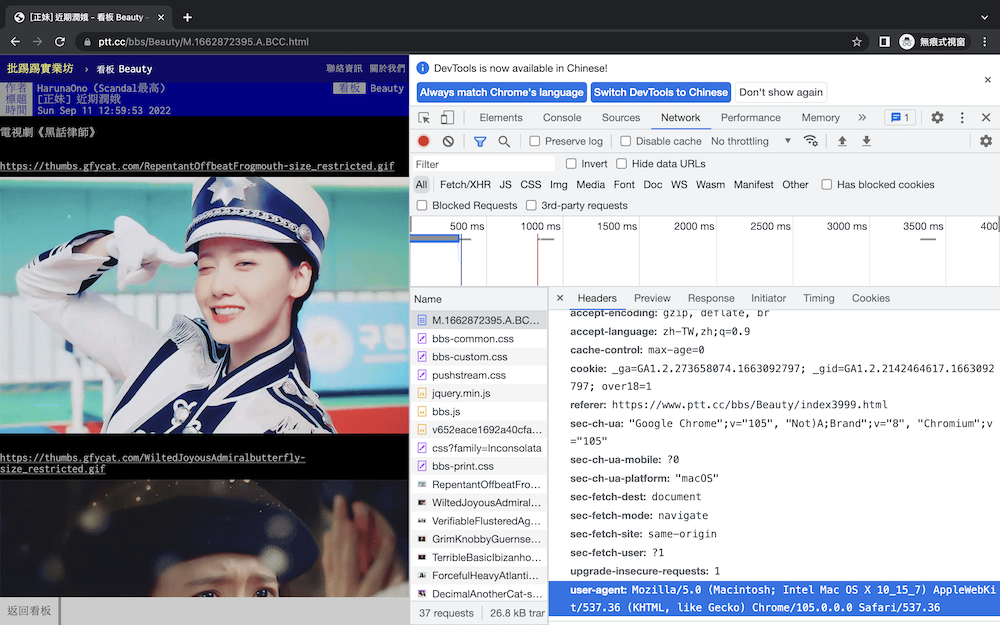
由於要下載的圖片副檔名不一定只有一種,所以我可以先把被允許的副檔名列出來。
allows = ["jpg", "jpeg", "png", "gif"] # 被允許的副檔名
links = html.find_all("a")
for link in links:
href = link["href"] # 取得網址
sub = href.split(".")[-1] # 取list中最後一個元素,也就是副檔名
if sub.lower() in allows: # 讓所有字母變成小寫
print("download:", href)
print("-" * 30)
下載的資料有兩種可能,分為純文字和非純文字:
dn = "ptt/" + url.split("/")[-1] # 資料夾檔名
if not os.path.exists(dn): # 如果沒有這個資料夾就創建一個
os.makedirs(dn)
allows = ["jpg", "jpeg", "png", "gif"] # 被允許的副檔名
links = html.find_all("a")
for link in links:
href = link["href"] # 取得網址
sub = href.split(".")[-1]
if sub.lower() in allows: # 讓所有字母變成小寫
print("download:", href)
response = requests.get(href, stream=True)
fp = dn + "/" + href.split("/")[-1] # 自己做檔名跟副檔名
f = open(fp, "wb")
f.write(response.raw.read()) # 把裡面的內容讀出來寫入新檔案
f.close()
print("-" * 30)
import os
import requests
from bs4 import BeautifulSoup
url = "https://www.ptt.cc/bbs/Beauty/M.1662872395.A.BCC.html"
dn = "ptt/" + url.split("/")[-1] # 資料夾檔名
if not os.path.exists(dn): # 如果沒有這個資料夾就創建一個
os.makedirs(dn)
response = requests.get(url, cookies={"over18":"1"})
html = BeautifulSoup(response.text, "html.parser")
allows = ["jpg", "jpeg", "png", "gif"] # 被允許的副檔名
links = html.find_all("a")
for link in links:
href = link["href"] # 取得網址
sub = href.split(".")[-1]
if sub.lower() in allows: # 讓所有字母變成小寫
print("download:", href)
fp = dn + "/" + href.split("/")[-1] # 自己做檔名跟副檔名
f = open(fp, "wb")
f.write(response.raw.read()) # 把裡面的內容讀出來寫入新檔案
f.close()
print("-" * 30)



 iThome鐵人賽
iThome鐵人賽